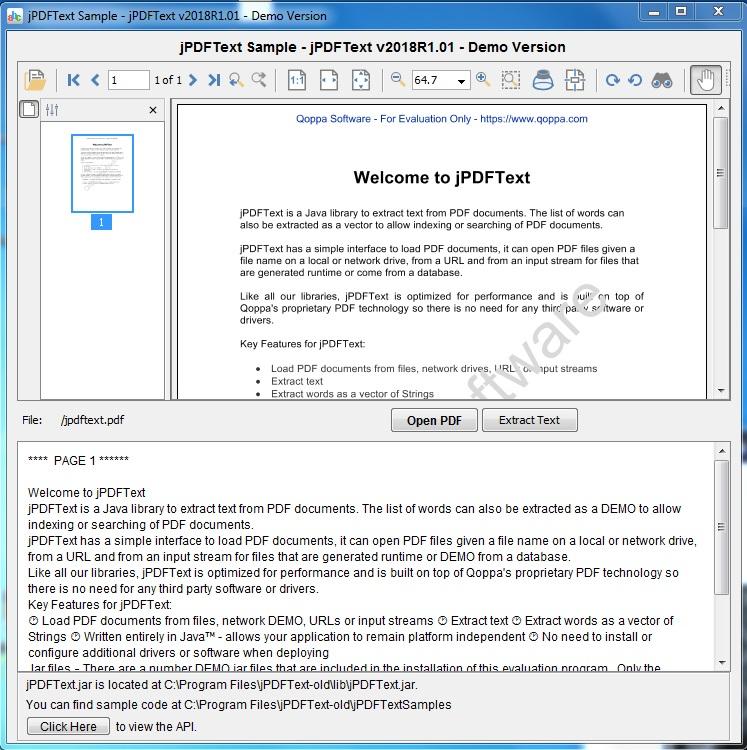
jPDFText ist eine Java-Bibliothek, um Text aus PDF-Dokumenten zu extrahieren. Mit jPDFText können PDF-Dokumente verarbeitet werden, um den textlichen Inhalt für die Archivierung, Speicherung, Suche oder Indizierung zu extrahieren. jPDFText basiert auf der proprietären PDF-Technologie von Qoppa, sodass Sie keine Software oder Treiber von Drittanbietern installieren müssen. Da es in Java geschrieben ist, kann Ihre Anwendung plattformunabhängig bleiben und unter Windows, Linux, Unix (Solaris, HP UX, IBM AIX), Mac OS X und jeder anderen Plattform ausgeführt werden, die die Java-Laufzeitumgebung unterstützt.
>
Haupteigenschaften:
Laden Sie PDF-Dokumente aus Dateien, Netzlaufwerken, URLs oder Eingabeströmen.
Extrahieren Sie Text in der logischen Lesereihenfolge.
Extrahiere Wörter als Vektor von Strings.
Funktioniert unter Windows, Linux, Unix und Mac OS X (100% Java).
Bei der Bereitstellung müssen keine zusätzlichen Treiber oder Software installiert oder konfiguriert werden.
Getestet auf JDK 1.4.2 und höher.
Kommentare nicht gefunden