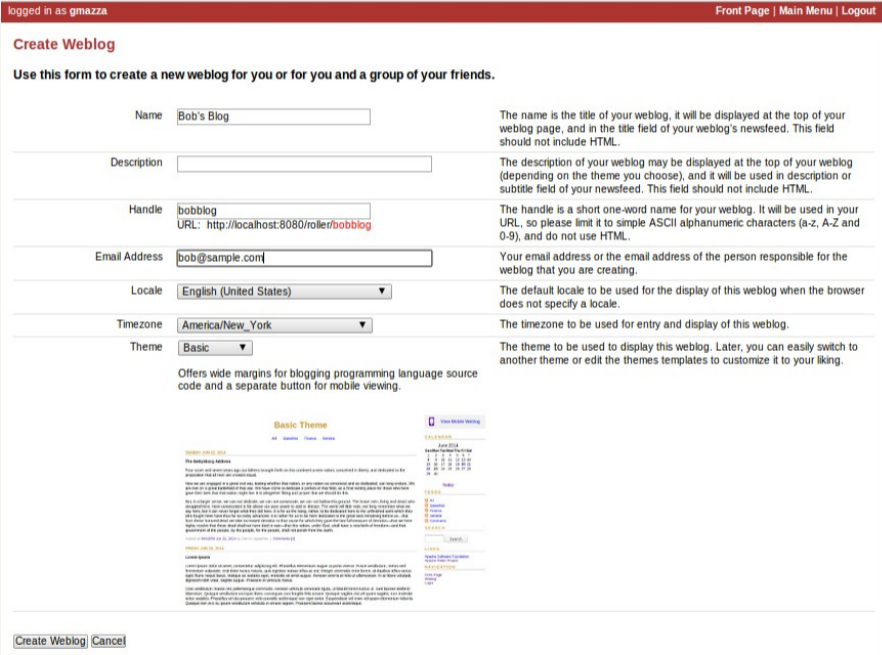
Screenshot der Software:
Softwarebeschreibung:
Version: 1.4.0 Aktualisiert
Upload-Datum: 9 Feb 16
Entwickler: Apache Software Foundation
Lizenz: Frei
Popularität: 33
Apache Drill wurde geschaffen, damit Entwickler zu 10.000 Server abzufragen und verarbeiten Petabyte Abfragedaten innerhalb von Sekunden.
Drill ist Apache Reaktion auf die Google-Dremel-Paket, eine Open-Source-Lösung für die Ausführung von großen Datenanalyse und Bereitstellung von Suchmaschinen, ohne ein Vermögen für Server und andere zusätzliche Technologien zu verbringen.
Das gesamte System mit Leistung konzipiert ist, Erweiterbarkeit und skalierbare Infrastrukturen
Was ist neu in dieser Version:.
- Keine Abhängigkeit von UDP-Multicast. Drill kann jetzt arbeiten auf EC2 sowie Cluster mit mehreren Subnetzen oder mehrfach Konfigurationen
- Automatische Partition Pruning basierend auf Verzeichnisstrukturen
- Neue verschachtelte Datenfunktionen: KVGEN und abflachen
- Fast & quot; Schema & quot; Rückkehr. Dies ermöglicht eine bessere Erfahrung, wenn BI-Tools mit
- Hive 0,13 Metastore Unterstützung
- Verbesserte Leistung für Abfragen auf JSON-Daten
Was ist neu in Version 1.3.0:
- Keine Abhängigkeit von UDP-Multicast. Drill kann jetzt arbeiten auf EC2 sowie Cluster mit mehreren Subnetzen oder mehrfach Konfigurationen
- Automatische Partition Pruning basierend auf Verzeichnisstrukturen
- Neue verschachtelte Datenfunktionen: KVGEN und abflachen
- Fast & quot; Schema & quot; Rückkehr. Dies ermöglicht eine bessere Erfahrung, wenn BI-Tools mit
- Hive 0,13 Metastore Unterstützung
- Verbesserte Leistung für Abfragen auf JSON-Daten
Was ist neu in der Version 1.0:
- Keine Abhängigkeit von UDP-Multicast. Drill kann jetzt arbeiten auf EC2 sowie Cluster mit mehreren Subnetzen oder mehrfach Konfigurationen
- Automatische Partition Pruning basierend auf Verzeichnisstrukturen
- Neue verschachtelte Datenfunktionen: KVGEN und abflachen
- Fast & quot; Schema & quot; Rückkehr. Dies ermöglicht eine bessere Erfahrung, wenn BI-Tools mit
- Hive 0,13 Metastore Unterstützung
- Verbesserte Leistung für Abfragen auf JSON-Daten
Was ist neu in Version 0.9.0:
- Keine Abhängigkeit von UDP-Multicast. Drill kann jetzt arbeiten auf EC2 sowie Cluster mit mehreren Subnetzen oder mehrfach Konfigurationen
- Automatische Partition Pruning basierend auf Verzeichnisstrukturen
- Neue verschachtelte Datenfunktionen: KVGEN und abflachen
- Fast & quot; Schema & quot; Rückkehr. Dies ermöglicht eine bessere Erfahrung, wenn BI-Tools mit
- Hive 0,13 Metastore Unterstützung
- Verbesserte Leistung für Abfragen auf JSON-Daten
Was ist neu in Version 0.8.0:
- Keine Abhängigkeit von UDP-Multicast. Drill kann jetzt arbeiten auf EC2 sowie Cluster mit mehreren Subnetzen oder mehrfach Konfigurationen
- Automatische Partition Pruning basierend auf Verzeichnisstrukturen
- Neue verschachtelte Datenfunktionen: KVGEN und abflachen
- Fast & quot; Schema & quot; Rückkehr. Dies ermöglicht eine bessere Erfahrung, wenn BI-Tools mit
- Hive 0,13 Metastore Unterstützung
- Verbesserte Leistung für Abfragen auf JSON-Daten
Was ist neu in Version 0.7.0:
- Keine Abhängigkeit von UDP-Multicast. Drill kann jetzt arbeiten auf EC2 sowie Cluster mit mehreren Subnetzen oder mehrfach Konfigurationen
- Automatische Partition Pruning basierend auf Verzeichnisstrukturen
- Neue verschachtelte Datenfunktionen: KVGEN und abflachen
- Fast & quot; Schema & quot; Rückkehr. Dies ermöglicht eine bessere Erfahrung, wenn BI-Tools mit
- Hive 0,13 Metastore Unterstützung
- Verbesserte Leistung für Abfragen auf JSON-Daten
Kommentare nicht gefunden