Kostenlose OCR-Software, um Text aus Bilddateien und PDF-Artikel zu extrahieren. Eine grafische Benutzeroberfläche (GUI) für das Tesseract OCR-Engine.
Die Anwendung ist einfach zu installieren und, noch wichtiger, frei, Open Source und 100% Adware und Spyware kostenlos nutzen.
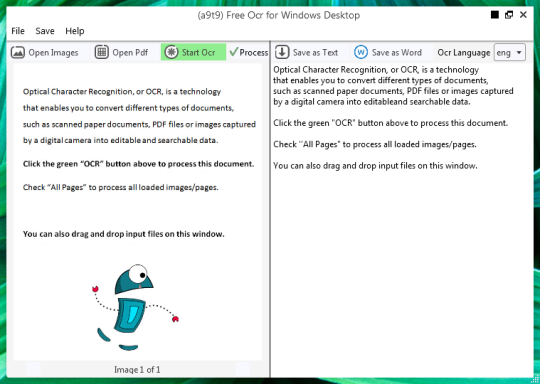
Sie können ein Bild oder PDF-Datei zu öffnen. Der Inhalt der Quelldatei wird in dem linken Fenster dargestellt. Wenn Sie Ihr Dokument als mehr als eine Seite, oder wenn Sie mehrseitige Dokumente geöffnet, benutzen Sie die Pfeile am unteren Rand, um zwischen ihnen zu wechseln,
Sie starten die OCR beim Anklicken des OCR-Taste, und Sie werden das Ergebnis im zweiten rechten Fenster zu sehen. Ausgangstext kann als Textdatei oder Word-Dokument gespeichert werden.
Leider ist die Qualität der Konvertierung ist nicht so groß. Hinter den Kulissen verwendet es die Tesseract Open-Source-OCR-Engine. Die Qualität variiert von Sprache zu Sprache. - So gehen Sie vor und testen, ob es für Ihre Bedürfnisse ausreichend ist
Für Software-Entwickler und Geeks: The Free OCR for Windows Desktop-Tool ist im Wesentlichen eine grafische Benutzerschnittstelle Front-End (GUI) für das Tesseract OCR-Engine. Der vollständige Quellcode ist verfügbar (GPL-Lizenz).
Die OCR-Engine der Software unterstützt die folgenden OCR-Sprache: Englisch, Französisch, Italienisch, Deutsch, Spanisch, brasilianisches Portugiesisch und Niederländisch. Ab der Version 3 ist Arabisch, Bulgarisch, Katalanisch, Chinesisch (vereinfacht und traditionell), Kroatisch, Tschechisch, Dänisch, Niederländisch, Englisch, Deutsch (Standard und Fraktur-Skript), Griechisch, Finnisch, Französisch, Hebräisch, Hindi, Ungarisch zu erkennen, Indonesisch, Italienisch, Japanisch, Koreanisch, Lettisch, Litauisch, Norwegisch, Polnisch, Portugiesisch, Rumänisch, Russisch, Serbisch, Slowakisch (Standard und Fraktur Schrift), Slowenisch, Spanisch, Schwedisch, Tagalog, Tamil, Thailändisch, Türkisch, Ukrainisch und Vietnamesisch.
Kommentare nicht gefunden