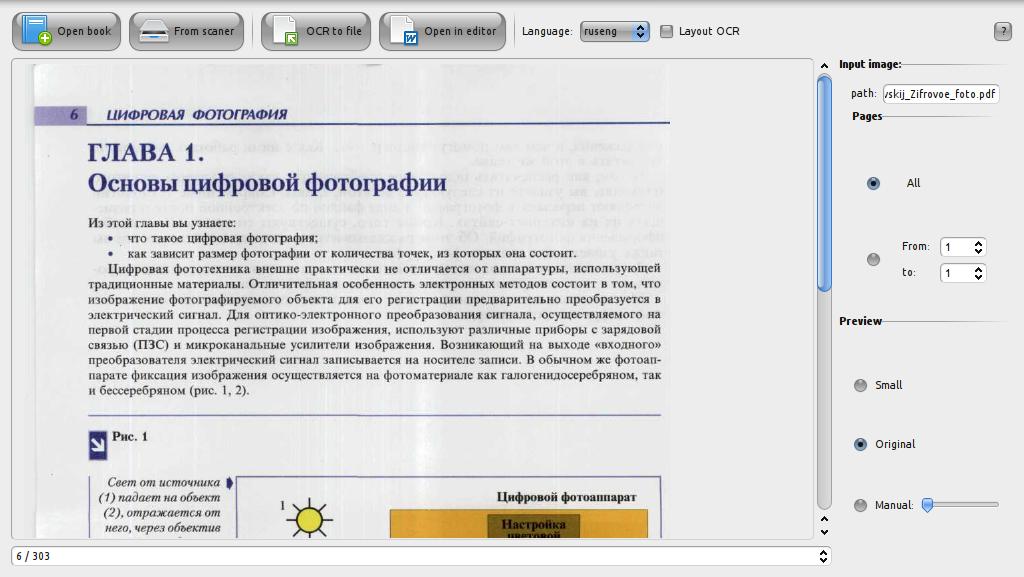
KBookocr ist ein intelligentes System für die Dokumentenerkennung (OCR-System).
Input: Geben Dokument, das Sie erkennen (djvu oder pdf) + Wählen Sie die Sprache der Eingabedokument soll.
Seiten, um fortzufahren: Scannen kann das gesamte Dokument oder ausgewählten Bereich durchgeführt werden.
Vorschau Größe: Hier ein paar Möglichkeiten der Vorschau (auf der linken Vorschaufensters):
Ureinwohner
Klein
Output: Ausgehende Dokumente können im txt-Format gespeichert werden (geben Sie den Ordner, den Sie speichern wollen) oder mit Openoffice geöffnet.
Basierend auf: CuneiForm
Anmerkung:. Die Qualität einer Ausgabedatei hängt von der Eingangsquelle Qualität und Arbeit der Dritt OCR-Paket
Was ist neu in dieser Pressemitteilung:
- Bessere KDE Integration, bessere UI, Pre-Build nur für x32
Was ist neu in der Version 2.0:
- neue Hauptversion von KBookOCR. Alles neu:
- neue GUI,
- neues Projekt System
- Neue Integration mit Keilschriftsystem,
- neue scaner Unterstützungssystem (KSane).
- Es ist stabiler, schneller als 1.x-Version
Was ist neu in Version 1.4.1:
- Sie können letzten Projekt zu laden und weiter zu arbeiten es.
Was ist neu in der Version 1.4 Beta:
- Buchseiten Vorschaubilder für die Erkennung, Batch-Scan-Option
Was ist neu in der Version 1.3:
- New GUI
Kommentare nicht gefunden