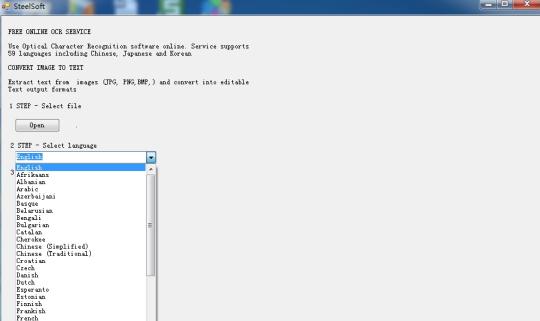
Erkennen von Text aus Bildern mit dem Tesseract OCR Engine auf Basis der Cloud-Technologie.
Verwenden Optical Character Recognition Software online. Service unterstützt 59 Sprachen, darunter Chinesisch, Japanisch und Koreanisch. Extrahieren von Text aus Bildern (JPG, PNG, BMP, TIF) und wandeln in bearbeitbaren Text-Ausgabeformate.
Es ist auf Cloud-Technologie und sehr berühmt OCR-Engine (Tesseract OCR Engine) basiert, so dass es nur hundert KB groß, aber es kann Text in 59 Sprachen zu extrahieren, aus den Bildern.
Es unterstützt mehrere Sprachen: Bulgarisch, Katalanisch, Tschechisch, Dänisch, Niederländisch, Englisch, Finnisch, Französisch, Deutsch, Griechisch, Ungarisch, Indonesisch, Italienisch, Lettisch, Litauisch, Norwegisch, Polnisch, Portugiesisch, Rumänisch, Russisch, Serbisch, Slowakisch, Slowenisch , Spanisch, Schwedisch, Tagalog, Türkisch, Ukrainisch, Vietnamesisch usw.
Was ist neu in dieser Pressemitteilung:..
Version 5.0 beinhaltet UE Verbesserungen

Kommentare nicht gefunden